
Introdução
O Kernel Memory (KM) é uma solução de inteligência artificial multimodal especializada na indexação de datasets. Utilizando pipelines híbridos de dados contínuos e personalizáveis, o KM oferece suporte a técnicas avançadas como:
- Retrieval Augmented Generation (RAG)
- Memória sintética
- Engenharia de prompts
- Processamento semântico customizado
O que é Kernel Memory?
O Kernel Memory destaca-se por sua capacidade de:
✅ Integrar diferentes tecnologias e ambientes
✅ Ser implantado em diversos contextos (Web App Services, Docker, ChatGPT plugins)
✅ Suportar múltiplos formatos de dados (Word, PDF, PowerPoint, vídeos)
✅ Ser open-source e extensível
✅ Oferecer performance otimizada para grandes volumes de dados
Arquitetura do Kernel Memory
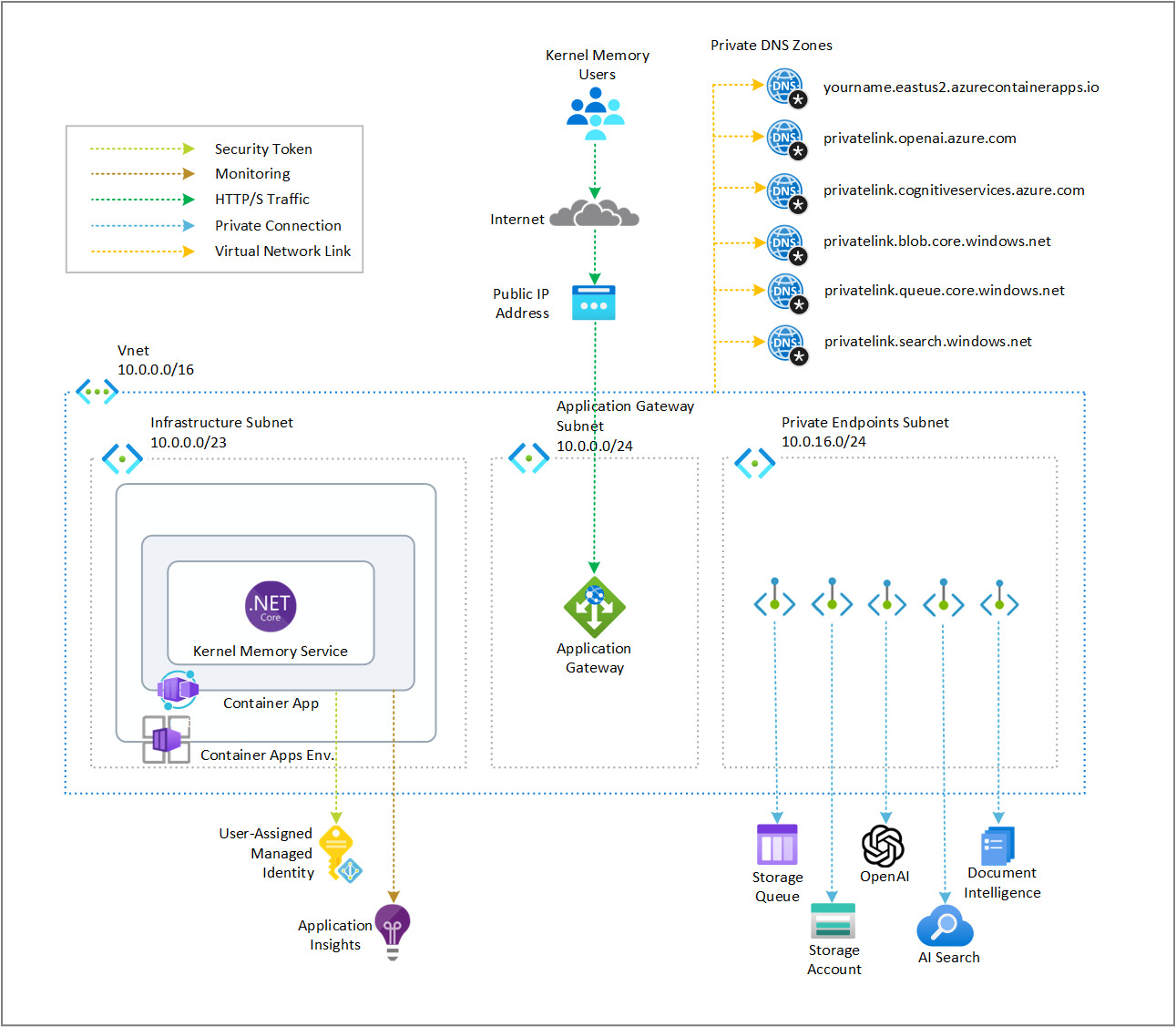
A arquitetura do Kernel Memory é baseada em:
Componentes Principais
-
Pipeline de Processamento
- Ingestão de documentos
- Extração de texto e metadados
- Vetorização com embeddings
- Indexação semântica
-
Storage Layer
- Armazenamento de documentos originais
- Índices vetoriais
- Metadados estruturados
-
Query Engine
- Busca semântica
- Recuperação de contexto
- Geração de respostas
Retrieval Augmented Generation (RAG)
RAG é uma arquitetura que combina modelos de linguagem de grande porte (LLMs) com sistemas de recuperação de informações, fornecendo:
Benefícios do RAG
- Dados atualizados e precisos
- Respostas contextualizadas baseadas em fontes confiáveis
- Melhoria na precisão das informações
- Redução de alucinações do modelo
- Transparência nas fontes utilizadas
Como Funciona
- Indexação: Documentos são processados e indexados semanticamente
- Recuperação: Busca-se informações relevantes na base de conhecimento
- Geração: O LLM gera respostas usando o contexto recuperado
Implementação Prática
Configuração Básica
using Microsoft.KernelMemory;
var memoryBuilder = new KernelMemoryBuilder()
.WithSearchClientConfig(new SearchClientConfig
{
EmptyAnswer = "Nenhuma informação foi encontrada para esta pergunta.",
AnswerTokens = 1000
})
.WithAzureOpenAITextEmbeddingGeneration(
deploymentName: "text-embedding-ada-002",
endpoint: "https://seu-recurso.openai.azure.com/",
apiKey: "sua-chave-api"
)
.WithAzureOpenAITextGeneration(
deploymentName: "gpt-4",
endpoint: "https://seu-recurso.openai.azure.com/",
apiKey: "sua-chave-api"
);
var memory = memoryBuilder.Build<MemoryServerless>();Importação de Documentos
// Importar documento PDF
await memory.ImportDocumentAsync(
filePath: "documento.pdf",
documentId: "doc001",
tags: new Dictionary<string, List<string>>
{
{ "categoria", new List<string> { "manual", "tecnico" } },
{ "departamento", new List<string> { "ti" } }
}
);
// Importar texto direto
await memory.ImportTextAsync(
text: "Conteúdo do documento...",
documentId: "doc002",
tags: new Dictionary<string, List<string>>
{
{ "fonte", new List<string> { "base-conhecimento" } }
}
);Consultas e Pesquisas
// Busca semântica
var searchResults = await memory.SearchAsync(
query: "Como configurar autenticação no sistema?",
filter: MemoryFilters.ByTag("categoria", "manual")
);
foreach (var result in searchResults.Results)
{
Console.WriteLine($"Documento: {result.SourceName}");
Console.WriteLine($"Relevância: {result.Relevance}");
Console.WriteLine($"Conteúdo: {result.Text}");
}
// Pergunta com contexto
var answer = await memory.AskAsync(
question: "Quais são os requisitos de sistema?",
filter: MemoryFilters.ByTag("departamento", "ti")
);
Console.WriteLine($"Resposta: {answer.Result}");
Console.WriteLine($"Fontes: {string.Join(", ", answer.RelevantSources)}");Demo em Funcionamento
Interface de Upload
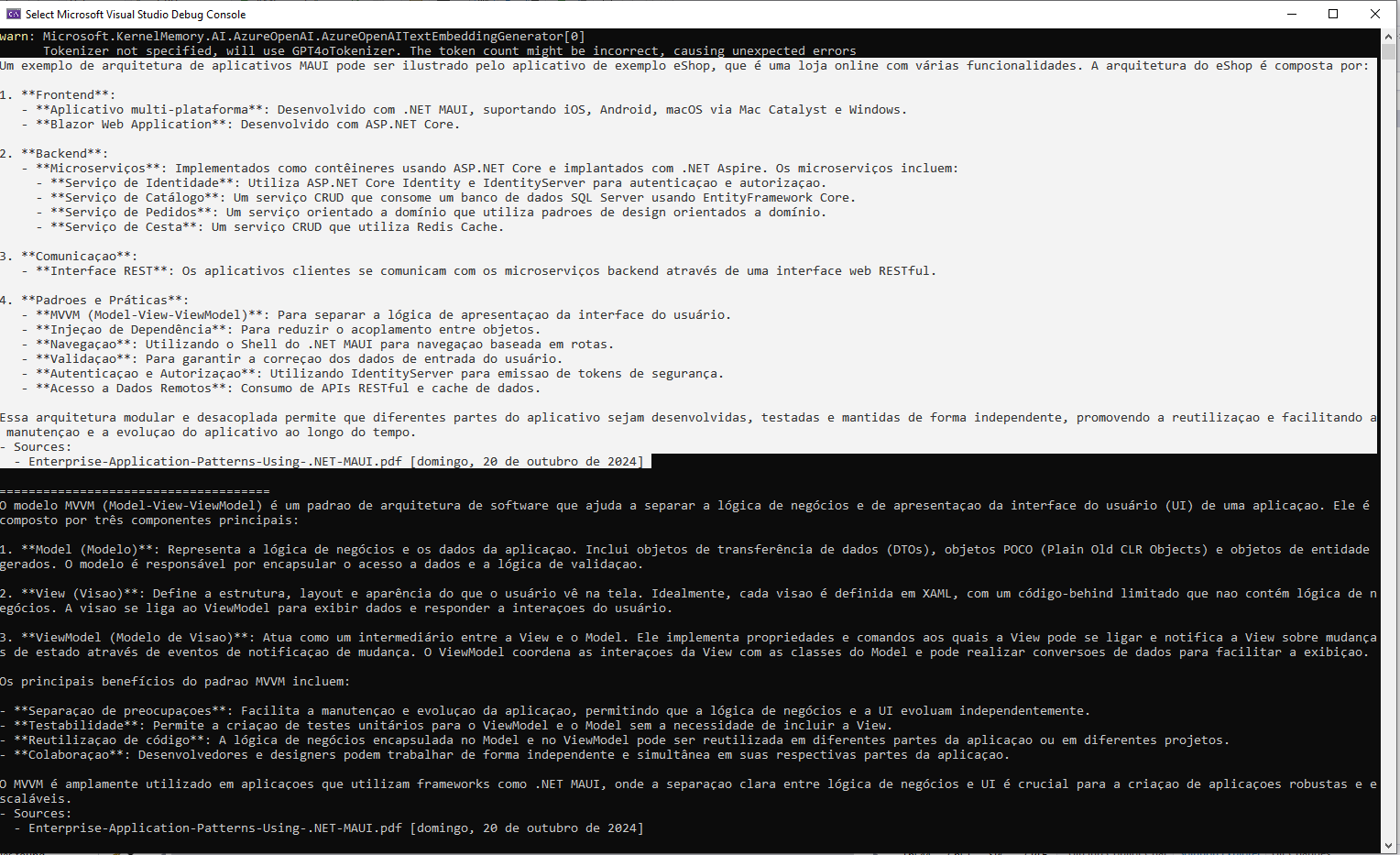
Resultados de Pesquisa
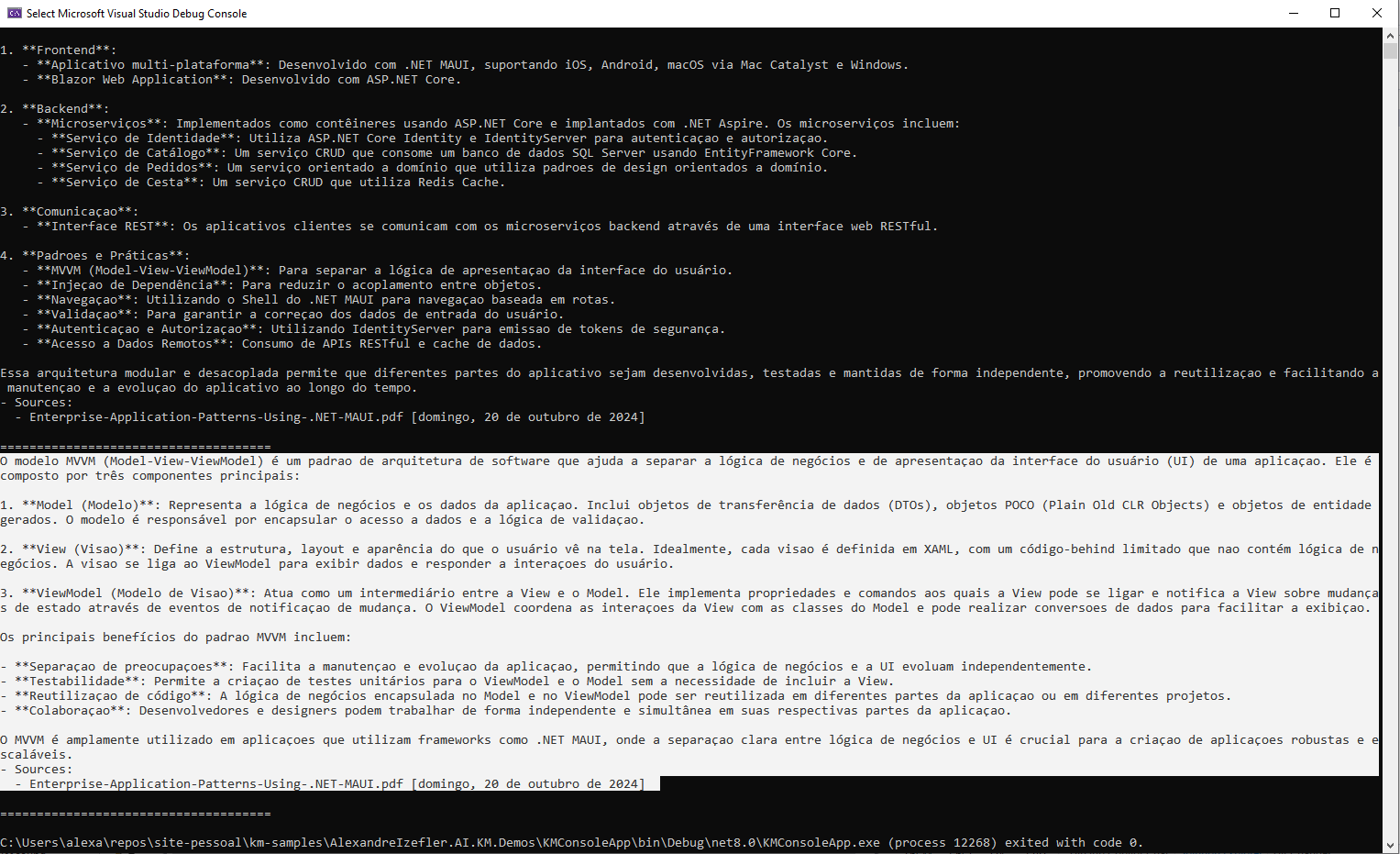
Casos de Uso Práticos
1. Base de Conhecimento Empresarial
// Configurar filtros por departamento
var memoria = new KernelMemoryBuilder()
.WithAzureOpenAI(config)
.Build();
// Importar manuais por departamento
await memoria.ImportDocumentAsync("manual-rh.pdf",
tags: new() { {"departamento", ["rh"]} });
await memoria.ImportDocumentAsync("manual-ti.pdf",
tags: new() { {"departamento", ["ti"]} });
// Consulta específica por departamento
var resposta = await memoria.AskAsync(
"Qual é a política de férias?",
filter: MemoryFilters.ByTag("departamento", "rh")
);2. Análise de Documentos Multimodais
// Processar diferentes tipos de documento
await memoria.ImportDocumentAsync("apresentacao.pptx");
await memoria.ImportDocumentAsync("planilha.xlsx");
await memoria.ImportDocumentAsync("video-treinamento.mp4");
// Buscar informações em todos os formatos
var resultado = await memoria.SearchAsync(
"Procedimentos de segurança no trabalho"
);3. Sistema de Suporte Técnico
public class SistemaSuporteTecnico
{
private readonly IKernelMemory _memoria;
public async Task<string> ResolverTicketAsync(string problema)
{
// Buscar soluções na base de conhecimento
var solucoes = await _memoria.SearchAsync(problema);
if (solucoes.Results.Any())
{
// Gerar resposta contextualizada
var resposta = await _memoria.AskAsync(
$"Como resolver: {problema}",
filter: MemoryFilters.ByTag("tipo", "solucao")
);
return resposta.Result;
}
return "Encaminhar para especialista.";
}
}Configurações Avançadas
Pipeline Customizado
var memoria = new KernelMemoryBuilder()
.WithCustomTextPartitioningOptions(new TextPartitioningOptions
{
MaxTokensPerParagraph = 1000,
MaxTokensPerLine = 300,
OverlappingTokens = 100
})
.WithCustomEmbeddingGenerationOptions(new EmbeddingGenerationOptions
{
EmbeddingDimensions = 1536
})
.Build();Conectores Personalizados
// Integração com SharePoint
var sharepointConnector = new SharePointConnector(config);
await memoria.ImportFromConnectorAsync(sharepointConnector);
// Integração com banco de dados
var dbConnector = new DatabaseConnector(connectionString);
await memoria.ImportFromConnectorAsync(dbConnector);Monitoramento e Performance
Métricas Importantes
public class MemoryMetrics
{
public async Task<PerformanceReport> GerarRelatorioAsync()
{
return new PerformanceReport
{
DocumentosIndexados = await CountDocumentsAsync(),
TempoMedioConsulta = await GetAverageQueryTimeAsync(),
PrecisaoRespostas = await CalculateAccuracyAsync(),
UtilizacaoRecursos = await GetResourceUsageAsync()
};
}
}Otimização de Custos
- Use caching para consultas frequentes
- Configure timeouts apropriados
- Monitore tokens consumidos
- Implemente rate limiting
Integração com Aplicações
API REST
[ApiController]
[Route("api/[controller]")]
public class MemoryController : ControllerBase
{
private readonly IKernelMemory _memoria;
[HttpPost("consultar")]
public async Task<IActionResult> ConsultarAsync([FromBody] ConsultaRequest request)
{
var resposta = await _memoria.AskAsync(request.Pergunta);
return Ok(new { resposta = resposta.Result, fontes = resposta.RelevantSources });
}
[HttpPost("importar")]
public async Task<IActionResult> ImportarAsync(IFormFile arquivo)
{
await _memoria.ImportDocumentAsync(arquivo.OpenReadStream(), arquivo.FileName);
return Ok("Documento importado com sucesso.");
}
}Interface Web
// Cliente TypeScript
class MemoryService {
async consultar(pergunta: string): Promise<RespostaMemoria> {
const response = await fetch('/api/memory/consultar', {
method: 'POST',
headers: { 'Content-Type': 'application/json' },
body: JSON.stringify({ pergunta })
});
return response.json();
}
async importarDocumento(arquivo: File): Promise<void> {
const formData = new FormData();
formData.append('arquivo', arquivo);
await fetch('/api/memory/importar', {
method: 'POST',
body: formData
});
}
}Boas Práticas
Estruturação de Dados
- Use tags significativas para categorização
- Mantenha metadados consistentes
- Segmente documentos grandes apropriadamente
- Configure overlapping para manter contexto
Segurança
// Configurar autenticação
var memoria = new KernelMemoryBuilder()
.WithAuthentication(new AzureADAuthentication())
.WithAuthorization(new RoleBasedAuthorization())
.Build();
// Filtros de segurança por usuário
var filtroUsuario = MemoryFilters.ByTag("acesso", usuario.Perfil);
var resposta = await memoria.AskAsync(pergunta, filter: filtroUsuario);Performance
- Configure índices adequadamente
- Use embeddings específicos para seu domínio
- Implemente cache para consultas frequentes
- Monitore latência e throughput
Casos de Sucesso
1. Empresa de Consultoria
- Desafio: Organizar 10 anos de relatórios técnicos
- Solução: KM com tags por projeto e cliente
- Resultado: 80% redução no tempo de busca
2. Suporte Técnico
- Desafio: Base de conhecimento fragmentada
- Solução: RAG com documentação unificada
- Resultado: 60% melhoria na resolução de tickets
3. Educação Corporativa
- Desafio: Treinamentos dispersos em múltiplos formatos
- Solução: Indexação multimodal com KM
- Resultado: 90% satisfação dos colaboradores
Futuro do Kernel Memory
Tendências
- Multimodalidade avançada (imagens, áudio, vídeo)
- Processamento em tempo real
- Integração com agentes autônomos
- Otimização automática de embeddings
Roadmap
- Suporte nativo para mais conectores
- Melhorias em performance e escalabilidade
- Ferramentas visuais de administração
- Integração com Microsoft 365
Conclusão
O Kernel Memory representa uma evolução significativa na forma como organizamos e acessamos informações empresariais. Sua capacidade de processar documentos multimodais e fornecer respostas contextualizadas através de RAG o torna uma ferramenta indispensável para:
✅ Modernização de bases de conhecimento
✅ Automação de processos de busca
✅ Melhoria na qualidade das respostas
✅ Redução de tempo na localização de informações
✅ Escalabilidade para grandes volumes de dados
A combinação do Kernel Memory com Azure OpenAI Services oferece uma solução robusta, segura e escalável para organizações que desejam aproveitar ao máximo seus ativos de informação.
Próximos Passos
- Avalie sua base de conhecimento atual
- Identifique casos de uso prioritários
- Implemente um piloto com documentos críticos
- Monitore performance e precisão
- Expanda gradualmente para toda organização
Recursos Adicionais
Alexandre Izefler é Arquiteto de Sistemas especializado em Azure e IA, com mais de 20 anos de experiência em desenvolvimento de soluções inovadoras.